
#57 closed ожидается проверка (задача сдана)
Кодирование Хаффмана
| Reported by: | Иван Кремнев | Owned by: | Vladimir Rutsky |
|---|---|---|---|
| Priority: | проверка | Milestone: | |
| Component: | HA#2 huffman | Version: | 1.0 |
| Keywords: | Cc: |
Description
Прошёл проверку с valgring.
У меня сразу возникли вопросы по cast'ам. Правомерно ли их использование в данном контексте?
Attachments (1)
{kind=link}
Change History (9)
comment:1 Changed 7 years ago by
| Milestone: | ha2-milestone1 → ha2-milestone2 |
|---|---|
| Type: | ожидается проверка → ожидаются исправления |
comment:2 follow-up: 3 Changed 7 years ago by
Спасибо за замечания! Да, на предложенных тестах uint32_t вполне хватило, хотя, возможно, и впритык.
Все исправления выполнены.
comment:3 Changed 7 years ago by
Replying to kremnev.ivan:
Спасибо за замечания! Да, на предложенных тестах uint32_t вполне хватило, хотя, возможно, и впритык.
Можете придумать тест, на котором uint32_t не хватит?
Changed 7 years ago by
| Attachment: | Безымянный.png added |
|---|
comment:4 follow-up: 6 Changed 7 years ago by
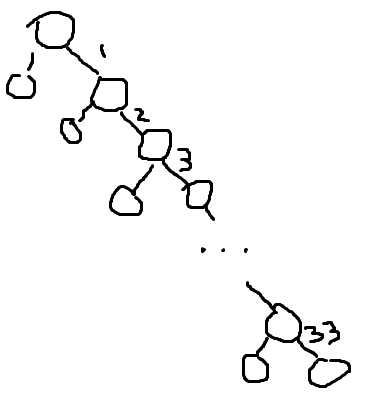
Чтобы не хватило 32 битов для кодирования символов, дерево Хаффмана должно иметь глубину 33, по крайней мере. Самый быстрый способ набрать такую глубину -- построить дерево из 33*2+1 вершины, в котором будет одна главная ветвь, на которой будут висеть листья по всей её длине.
Различных байтов в исходном документе требуется как минимум 34. При этом каждый байт из более высокого уровня должен иметь частоту, не меньшую суммы частот всех байтов из нижнего уровня. То есть в исходном документе частоты байтов должны расти как минимум по закону
fi = f0 + f1 + ... + fi-1
Если f0 = 1, f1 = 1, то
f2 = 1 + 1 = 2
f3 = f0 + f1 + f2 = 2*f2 = 4
f4 = f0 + f1 + f2 + f3 = 2*f3 = 8
...
f33 = 232
Получается, что минимальный исходный документ, требующий более 32 битов для кодирования по Хаффману содержит 34 различных байта с частотами 1, 1, 2, ... , 232. Размер такого документа составляет
1 + 1 + 2 + 4 + ... + 232 = 233 байтов, т.е. 8 Гб.
comment:5 Changed 7 years ago by
| Type: | ожидаются исправления → ожидается проверка |
|---|
comment:6 Changed 7 years ago by
| Resolution: | → задача сдана |
|---|---|
| Status: | new → closed |
Replying to kremnev.ivan:
Чтобы не хватило 32 битов для кодирования символов, дерево Хаффмана должно иметь глубину 33, по крайней мере. Самый быстрый способ набрать такую глубину -- построить дерево из 33*2+1 вершины, в котором будет одна главная ветвь, на которой будут висеть листья по всей её длине.
Различных байтов в исходном документе требуется как минимум 34. При этом каждый байт из более высокого уровня должен иметь частоту, не меньшую суммы частот всех байтов из нижнего уровня. То есть в исходном документе частоты байтов должны расти как минимум по закону
fi = f0 + f1 + ... + fi-1
В целом рассуждения хорошие, но данное утверждение неверно.
Например, символы, встречающиеся 1, 1, 2, 3, 5, 8 раз создадут описанное выше вытянутое дерево:
20
/ \
8 12
/ \
5 7
/ \
3 4
/ \
2 2
/ \
1 1
Если f0 = 1, f1 = 1, то
f2 = 1 + 1 = 2
f3 = f0 + f1 + f2 = 2*f2 = 4
f4 = f0 + f1 + f2 + f3 = 2*f3 = 8
...
f33 = 232
Получается, что минимальный исходный документ, требующий более 32 битов для кодирования по Хаффману содержит 34 различных байта с частотами 1, 1, 2, ... , 232. Размер такого документа составляет
1 + 1 + 2 + 4 + ... + 232 = 233 байтов, т.е. 8 Гб.
Можно доказать, что минимальный тест, дающий вытянутое дерево с кодами из более чем 32-бита будет более 5 МБ, что превышает ограничения, указанные в условии задачи.
Решение зачтено.
Это корректное использование
reinterpret_cast:Здесь не подходит динамическое приведение типа (
dynamic_cast) и не подразумевается статическое приведение типа (static_cast), здесь вы именно хотите посмотреть на область памяти, которая представлена указателем одного типа, как на массив байт ---reinterpret_castпредназначен именно для такой операции.Замечения:
// huffman.hpp struct ByteFrequency { ... ByteFrequency(uint8_t byte, uint32_t frequnecy, bool is_leaf, size_t left, size_t right); ... // huffman.cpp ByteFrequency::ByteFrequency( uint8_t byte = 0, uint32_t frequency = 0, bool is_leaf = true, size_t left = 0, size_t right = 0): basic_byte(byte), frequency(frequency), leaf(is_leaf), left(left), right(right) {}Вопрос: всегда ли вам хватает uint32_t для представления кода символа?
Исправьте, пожалуйста, в течение 60 часов.